 GPT4Point: A Unified Framework for Point-Language Understanding and Generation
GPT4Point: A Unified Framework for Point-Language Understanding and Generation
Abstract
Multimodal Large Language Models (MLLMs) have excelled in 2D image-text comprehension and image generation, but their understanding of the 3D world is notably deficient, limiting progress in 3D language understanding and generation. To solve this problem, we introduce GPT4Point, an innovative groundbreaking point-language multimodal model designed specifically for unified 3D object understanding and generation within the MLLM framework. GPT4Point as a powerful 3D MLLM seamlessly can execute a variety of point-text reference tasks such as point-cloud captioning and Q&A. Additionally, GPT4Point is equipped with advanced capabilities for controllable 3D generation, it can get high-quality results through a low-quality point-text feature maintaining the geometric shapes and colors. To support the expansive needs of 3D object-text pairs, we develop Pyramid-XL, a point-language dataset annotation engine. It constructs a large-scale database over 1M objects of varied text granularity levels from the Objaverse-XL dataset, essential for training GPT4Point. A comprehensive benchmark has been proposed to evaluate 3D point-language understanding capabilities. In extensive evaluations, GPT4Point has demonstrated superior performance in understanding and generation.
🔥Highlight
- Unified Framework for Point-language Understanding and Generation. We present the unified framework for point-language understanding and generation GPT4Point, including the 3D MLLM for point-text tasks and controlled 3D generation.
- Automated Point-language Dataset Annotation Engine Pyramid-XL. We introduce the automated point-language dataset annotation engine Pyramid-XL based on Objaverse-XL, currently encompassing 1M pairs of varying levels of coarseness and can be extended cost-effectively.
- Object-level Point Cloud Benchmark. Establishing a novel object-level point cloud benchmark with comprehensive evaluation metrics for 3D point cloud language tasks. This benchmark thoroughly assesses models' understanding capabilities and facilitates the evaluation of generated 3D objects.
GPT4Point-Usage
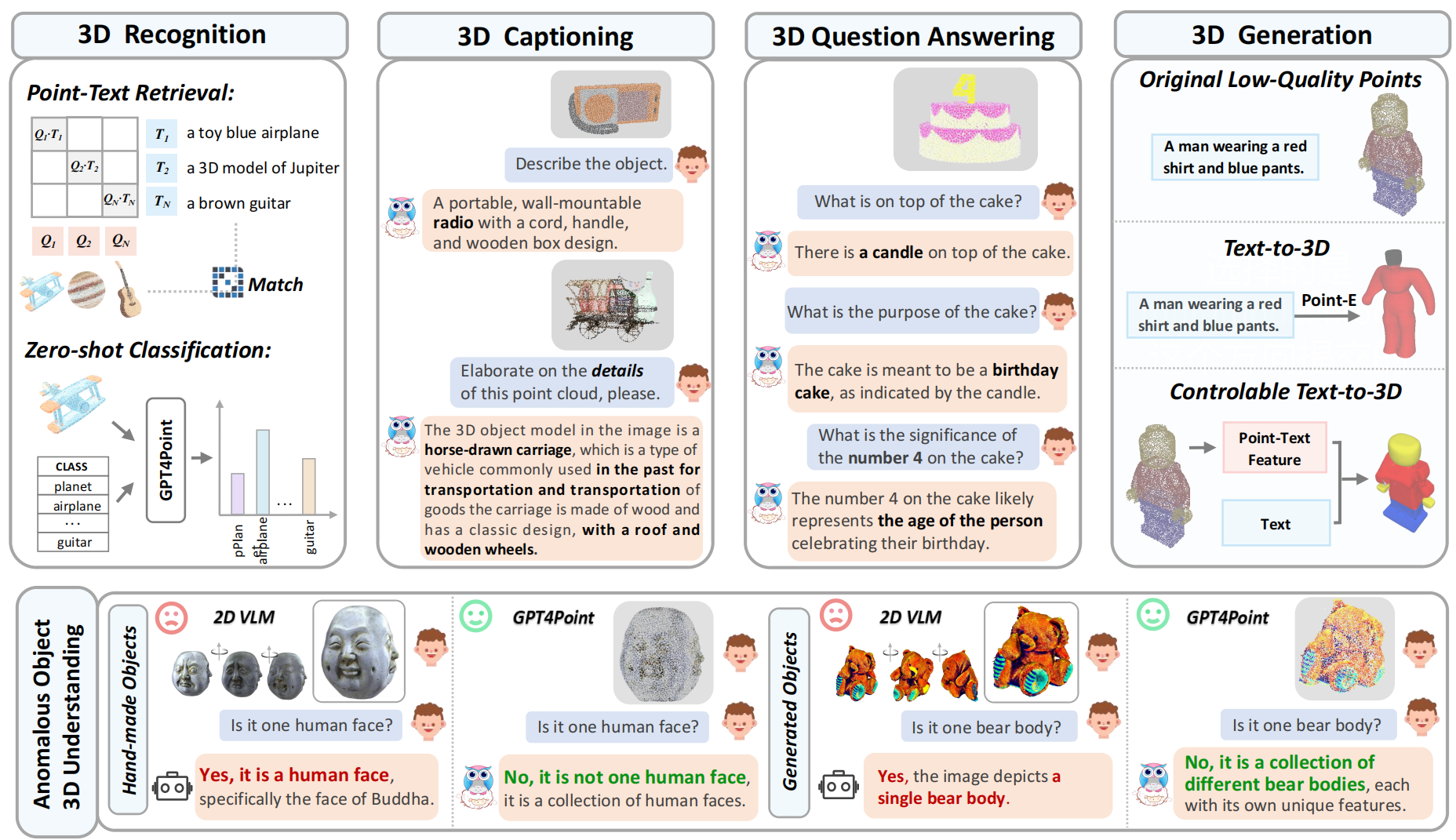
Task examples of GPT4Point. It performs accurate 3D recognition, detailed captioning, precise Q&A, and high-quality controllable 3D generation. Additionally, GPT4Point excels in 3D anomalous object description, accurately assessing abnormal shapes like the multi-face object and the 3D generation failure case.
It is a crucial ability in the assessment of generated 3D objects.
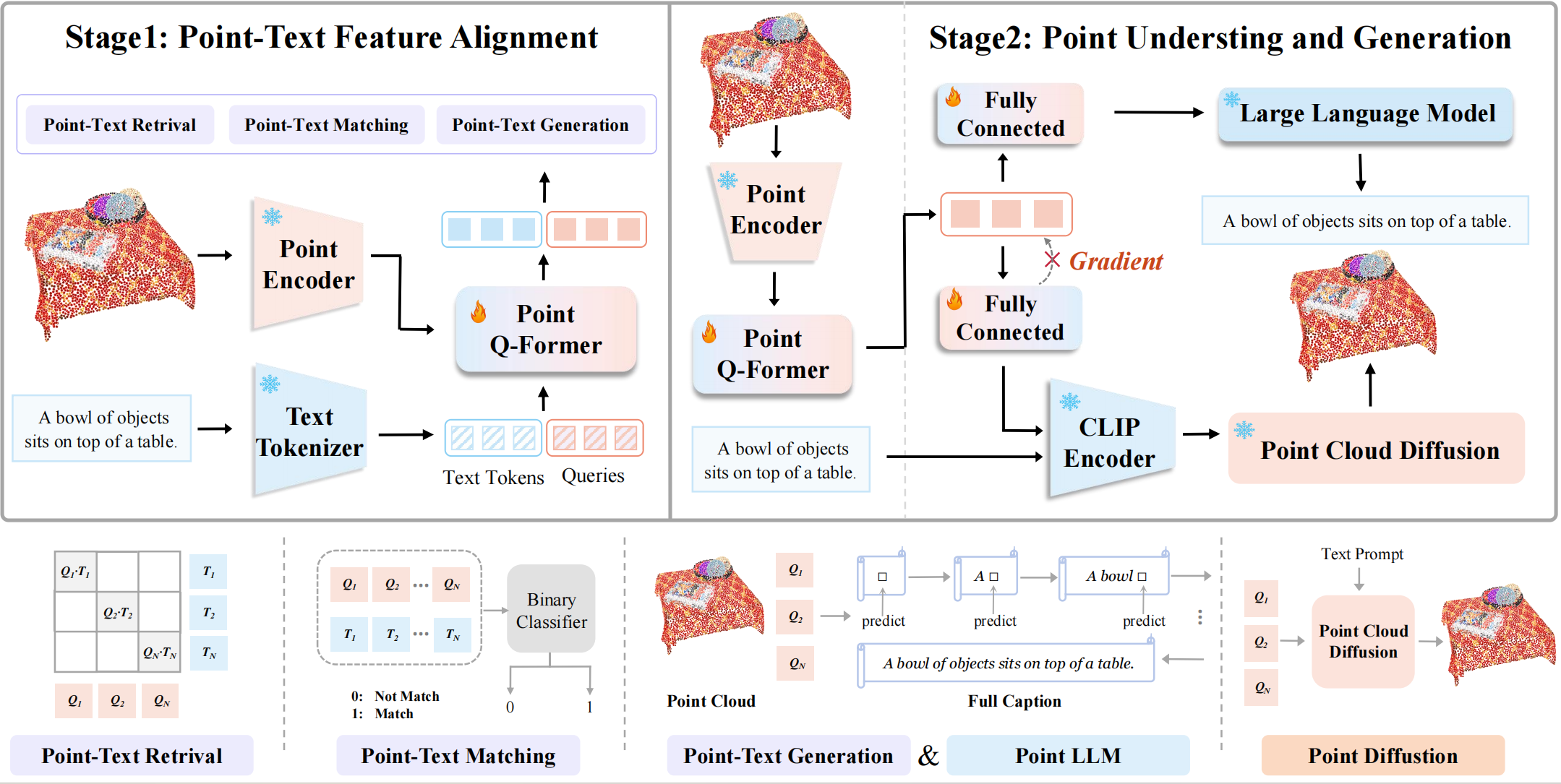
GPT4Point Pipeline
The model architecture of GPT4Point for training. In Stage1, we employ a Bert-based Point-Q-Former for point-text feature alignment through three point-text tasks. Then, in Stage2, an LLM is appended to train the model's text inference capabilities.
A Point Cloud Diffusion is attached separately to train controlled text-to-3D generation which keeps the geometry shape and colors.
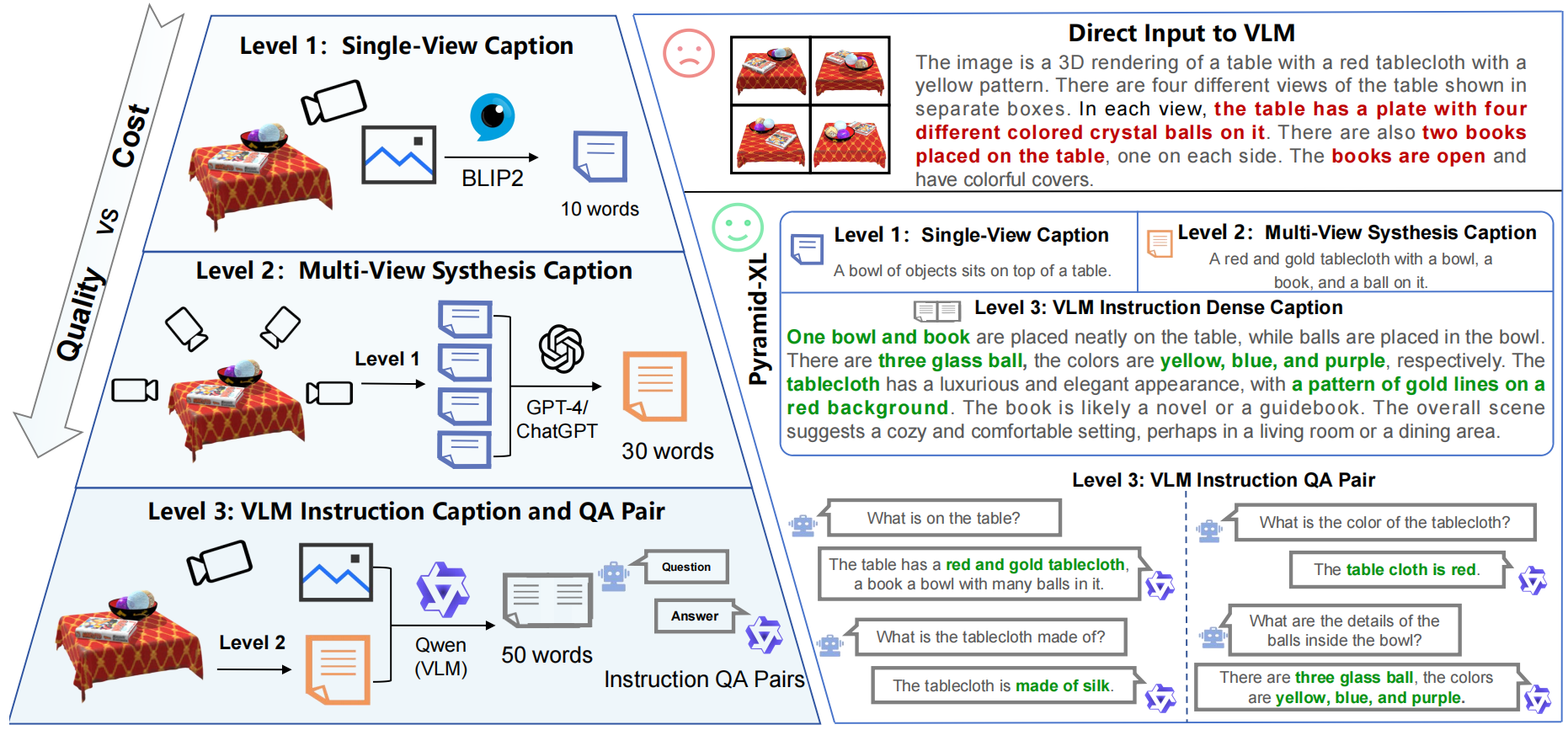
Pyramid-XL: An automated point-text annotation engine
Pyramid-XL: An automated point-text annotation engine. Directly inputting images into VLMs yields unsatisfactory results.
We propose a progressive annotation approach with 3 levels of granularity, leveraging results from the previous level for precise outcomes.
GPT4Point: Long Caption and Question & Answering
Examples of text inference using the GPT4Point with ViT-g and OPT6.7B after Instruct Finetuning. The table showcases
its proficiency with point cloud input, excelling in tasks like detailed caption generation and point cloud-bas question answering. This
underscores our model's profound grasp of point cloud geometry and color, translating them into meaningful semantics.
GPT4Point: Detect Anomalous Objects(Generation Failure Cases)
Anomalous Objects: Generation Failure Cases. The upper and lower parts respectively depict the performance of 2D
MLLM and GPT4Point in identifying abnormally generated objects with multi-body and multi-head structures. GPT4Point is effective in
making accurate judgments, whereas 2D MLLM, due to the lack of information from single-view images, fails to identify most cases.

GPT4Point: Point Diffusion Results
Point Diffusion Results: our controllable text-to-3D. Given a low-quality point cloud prior, it can generate outcomes
superior to direct text-to-3D and image-to-3D methods and more closely align with the low-quality priors, demonstrating controllability.

Pyramid-XL Level 3 Point-E Finetune Results.
Pyramid-XL Level 3 Point-E Finetune Results. We found that the results of fine-tuning with dense captions from our
Pyramid-XL significantly outperform those fine-tuned with Cap3D captions, demonstrating the greater accuracy of our generated captions.
BibTeX
@misc{qi2023gpt4point,
title={GPT4Point: A Unified Framework for Point-Language Understanding and Generation},
author={Zhangyang Qi and Ye Fang and Zeyi Sun and Xiaoyang Wu and Tong Wu and Jiaqi Wang and Dahua Lin and Hengshuang Zhao},
year={2023},
eprint={2312.02980},
archivePrefix={arXiv},
primaryClass={cs.CV}
}